

Deliver Powerful Insights Instantaneously with Federated Queries - No Matter Where Your Data Resides
The concept of federated queries isn’t new. Facebook PrestoDB popularized the idea of distributed structured query language (SQL) query engines in 2013.
Over the years, AWS, Google, Microsoft, and many others in the industry have accelerated the adoption of a distributed query engine model within their products. For example, AWS developed Amazon Athena on top of the Presto code base, while Google’s BigQuery is based on Cloud SQL.
What’s All the Buzz About Query Federation?
Once a SaaS business receives the funding and expands to 25 to 50 employees, its organizational structure will be slightly different. But the employees will typically still fit into the three categories:
Presto simplified this by enabling the querying of relational and non-relational databases and object stores - or disparate sources as you can call it collectively - via SQL, allowing for easier access to data from BI tools and even organizations’ own code.

Facilitating access to data from multiple sources in a single query, and that too fast is what is so revolutionary about Query Federation. It’s because consolidating data from different sources used to be a long, tedious process. You need Extract, Transform, Load (ETL) processes to bring data together into a shared format.
But ETL tools typically aren’t considered suitable by the community experts if you are looking for near-real-time or on-demand data access. They were designed for a batch mode of working where commands are read and acted upon as a batch without user intervention. ETL was more suited for established, slow-changing data. Also, ETL is not accessible to data analytics and business users directly.
The benefits of federated queries are immense compared to the traditional querying approaches of other database solutions. Here are a few:
Federated queries make it easier for data scientists and analysts to analyze data as the traditional ETL tools were geared more toward developers and coders who understood database language.
Federated queries are usually optimized before execution, enabling hundreds of user queries to be load-balanced and de-duplicated in real-time. This leads to higher throughput and lowers costs when using advanced analytics or business intelligence tools, promoting data-driven decision-making.
The biggest advantage is that the users don’t need to know the specific query or data language for each database. Automated Data Definition Language (DDL) conversion in federated queries allows anyone to perform queries on all data sources.
Trianz’ Approach to Query Federation
Our extensive study on digital transformations finds that over 90% of IT and data leaders are planning to use either multi-cloud or hybrid cloud architectures. Applications and data are therefore highly unlikely to be consolidated on a single cloud platform – be it AWS, Azure, GCP, IBM or your private virtualized environment.
This means that data will increasingly get distributed across data sources and become difficult to manage. While data lakes are one desirable solution, consolidating all enterprise data into a lake and continuously updating it can be expensive.
Looking for the fastest way to analyze data stored in Amazon S3?
Users simply point Athena at data stored in their S3 bucket, identify their fields, run the queries, and get results back in seconds.
Amazon’s new Athena platform uses federated queries that enable quick and easy SQL queries across data stored in several relational, non-relational, object, and custom data sources. Using data source connectors that run on AWS Lambda, data scientists, engineers, and analysts can analyze data from multiple sources running on-prem or the cloud with a single SQL query.
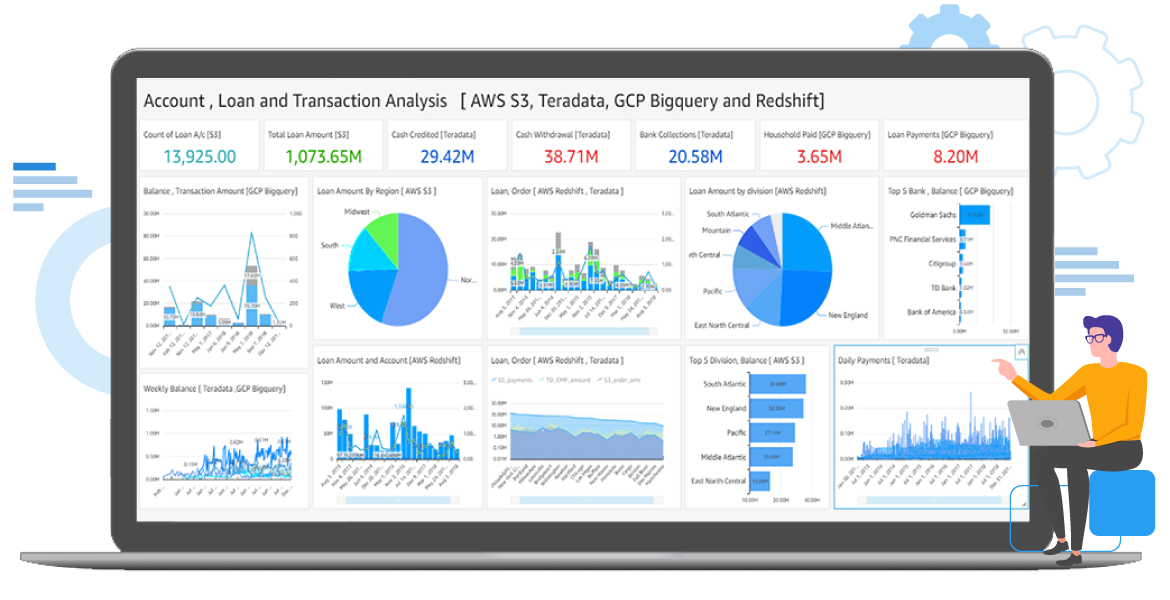
Trianz has built Athena Federated Query (AFQ) extensions on top of the Athena platform to simplify BI and facilitate cross-data-source analytics. These extensions typically scan data from S3 and execute the Lambda-based connectors to read data from on-prem Teradata, Amazon Redshift, Google BigQuery, and SAP HANA.
With a complete ecosystem of Trianz and AWS AFQ connectors, you can produce hybrid/multi-cloud analytics and visualizations without migrating or consolidating your data. The combined library of AFQ connectors can pull data from literally any source in your enterprise or other cloud platforms such as Azure or GCP.
Our AFQ connectors have been tested and tried by Amazon and large, complex data organizations in Fortune 1000 companies. The power of Athena is to allow technical and non-technical users to generate rich, powerful visualizations with simple queries, and saves time and resources in the long run.
Experience the Trianz Difference
Trianz enables digital transformations through effective strategies and excellence in execution. Collaborating with business and technology leaders, we help formulate and execute operational strategies to achieve intended business outcomes by bringing the best of consulting, technology experiences and execution models.
Powered by knowledge, research, and perspectives, we enable clients to transform their business ecosystems and achieve superior performance by leveraging infrastructure, cloud, analytics, digital and security paradigms. Reach out to get in touch or learn more.