

How Is an ODS Different from a Data Warehouse?
To better understand the difference between an operational data store (ODS) and a data warehouse, it is best to clarify that an ODS is not a replacement or substitute for a data warehouse. While an ODS is often an intermediary or staging area for a data warehouse, the ODS differs in that its data is overwritten and changes frequently. In contrast, a data warehouse contains static data for archiving, storage, historical analysis, and reporting.
However, an ODS and a data warehouse have much in common as they both import and consolidate data from disparate sources. These sources provide a key function for analysis and reporting, but it is important to distinguish the nuances between the two to decide whether to deploy one integrated data solution or combine them within a tiered data architecture to deliver the most business intelligence (BI) for your organization.
The ODS in Action
A Fortune 100 P&C insurer in the US found it challenging to manage operations efficiently with slow development life cycles, limited data processing capability, and heavy dependence on IT. They were looking for low-cost infrastructure and analytics solutions as they migrated their existing applications to event-based architecture.
Knowing there was a better way, they set out to deploy an intelligent, state-of-the-art ODS and analytics solution. To learn how we migrated their existing applications to event-based architecture, read this case study on deploying a next-gen operational data store.
Looking for a faster way to query data from your ODS and data warehouse?
Amazon Athena Federated Query Connectors make it possible to connect and query multiple databases outside the AWS ecosystem.
What Is a Data Warehouse?
A data warehouse is a system used for reporting and data analysis that acts as the central repository of data integrated from disparate sources. Data warehouses store unstructured, structured, and semi-structured data to offer organizations a single source of truth (SSOT) for long-term strategic planning.
Most data warehouses include the following elements:
- A relational database (RDB) to store large amounts of business data related to customers, orders, or products.
- An extraction, loading, and transformation (ELT) solution used to prepare big data for statistical analysis, reporting, and data mining capabilities.
- Client-side visualization tools for presenting data to business users.
- Advanced data warehouses often include sophisticated applications that generate actionable information by applying data science and artificial intelligence (AI) algorithms.
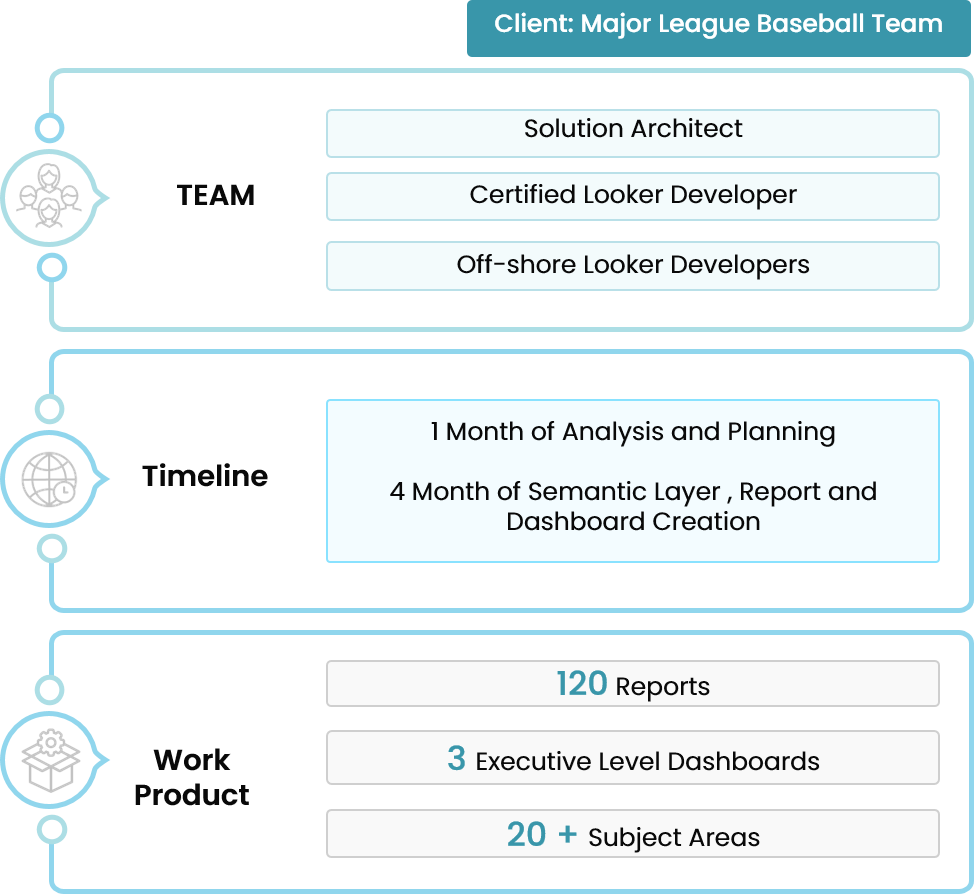
How a Midwest Sports Team Stepped Up Its BI Game
Data warehouses can be deployed on-premises, in the cloud, or in a hybrid cloud environment. Most data warehouses are hosted on a cloud service, which offers a more scalable and cost-effective solution to on-premises infrastructures. The most popular cloud data warehouse options include:
1. Amazon Redshift is a fully managed, AWS cloud-based data warehousing platform. Redshift is an excellent choice for enterprises that have an existing relational database management system (RDBMS), such as MySQL, PostgreSQL, and Oracle DB.
2. Azure SQL Data Warehouse is a Microsoft managed petabyte-scale service with controls to manage compute and storage independently. It is best for users looking to pause the compute layer while persisting the data to reduce operational costs in a pay-as-you go environment.
3. Google BigQuery is a serverless, highly scalable, and cost-effective multi-cloud data warehouse designed for interactive analysis of massive datasets. Google offers integrated machine learning and business intelligence tools, such as BigQuery ML and BigQuery BI Engine to support advanced analytics capabilities
4. SAP Data Warehouse Cloud is a SAAS cloud solution that includes data integration, database, data warehouse, and analytics capabilities to help organizations build a data-driven enterprise.
5. Snowflake is an ANSI-standard SQL columnar store database designed for big data analytics. Snowflake is best suited for organizations running complex queries, doing data analytics, or big data science.
Benefits of a Data Warehouse
In addition to a data warehouse providing the analytic capabilities to improve business decision-making, here are five more ways a DW gives businesses a key competitive advantage.
Rich historical data
When properly formatted, the accurate data that a data warehouse provides is essential for allowing decision-makers to learn from past trends and challenges. A data warehouse can add context to historical data by listing all the key performance trends surrounding previous strategies — something that cannot be accomplished with a traditional database.
More security options
Whether on-premise or in the cloud, a data warehouse can ensure data security by using encryption and specific protection setups such as “slave read only” to block malicious SQL code and protect confidential data.
Greater scalability
Data warehouses are key components for providing organizations with the scalability they need to keep operations running smoothly. The ability to handle more queries and scale up and down during peak demand helps generate more scalability in the overall business.
Better strategy
By using historical data to enable smarter, metric-based decision-making on everything from inventory to key sales to product releases, organizations can create a competitive strategy that doesn’t rely on intuition.
High ROI
A data warehouse empowers organizations to answer vital questions such as: What is the value of the available data assets? Can stakeholders access our data in real-time? Can data streams be monetized? What is the value of the available data assets? The ability to answer these questions provides organizations with a data warehouse payback period of fewer than two years.
Disadvantages of a Data Warehouse
One of the major drawbacks of a data warehouse is its non-volatile nature, meaning the data is read-only and requires cleansing. This leads to time variance, which means that data warehouse updates are performed in scheduled batches, leading to the possibility of dated reporting.
For this reason, many organizations choose to implement an ODS as a staging area to integrate operational data for day-to-day functioning.
What Is an Operational Data Store?
An operational data store is a cost-effective solution to the non-volatile nature of data warehouses. An ODS does not require the same type of transformations as a data warehouse. Since an ODS can only store structured data, the data remains in its existing schema, making it more like a data lake, which uses the schema-on-write approach.
In this sense, the ODS acts as a repository that stores a snapshot of an organization's most current data, making it easier for users to diagnose problems before searching through component systems. For example, an ODS allows service representatives to immediately query a transaction to answer:
- Where is the customer’s package currently located?
- Why is the transaction not going through?
- What steps can I take to further troubleshoot this problem?
Since the staging area receives operational data from transactional sources in near-real-time, the burden is offloaded from the transactional systems by only providing access to current data that is being queried. This makes an ODS the ideal solution for those looking for a 360-degree view of information connected to current data records to make faster business decisions.
Benefits of an Operational Data Store
How can your business benefit from an operational data store? Here are five compelling reasons why you should consider an ODS to offer your business the speed, scale, and agility it needs in a snapshot glance.
Cost-effective
An ODS is much cheaper to build and implement than data warehouses and data lakes. While prices vary dramatically based on operating requirements and use cases, an ODS typically costs about a tenth of what businesses can expect to pay for an on-premise data warehouse.
Rapid querying
Since an operational data store collects only current data, querying is simplified by bypassing the need for multi-level joins. This is particularly helpful when locating data to answer pressing transactional questions on the fly.
Better data quality
Since an ODS acts as a staging area, it can configure the data into one consistent format. This improves the overall data quality before being sent into the data warehouse, where it will be used for strategic decision-making.
Faster tactical decision making
An ODS provides time-sensitive business data that would be impossible to locate when embedded in disparate source systems. Since an ODS extracts real-time operational data, it simplifies the reporting process and greatly improves efficiency by consolidating that information in a snapshot repository.
Faster time to market
A next-generation ODS can reduce manual schema mapping to just a single click. With a microservices architecture, organizations are enabled to bring new services to market faster.

Disadvantages of an Operational Data Store
Traditional ODS solutions typically suffer from high latency because they are based on either relational databases or disk-based NoSQL databases. These systems simply cannot handle large amounts of data and provide high performance simultaneously.
The limited scalability of traditional systems also leads to performance issues when multiple users access the data store at the same time. As such, traditional ODS solutions cannot provide real-time API services for accessing systems of record.
In short, it depends on your use cases and the amount of data being analyzed. If your organization anticipates an overwhelming amount of client, employee, and customer account information, then an ODS solution should be integrated with a data warehouse system.
Mergers or acquisitions are another factor to consider for creating a tiered architecture. To enable a central view of current and historical data across multiple source systems, combining an ODS and data warehouse will offer the most relevant snapshot of the entire enterprise.
"In this digital age, where the cloud promises much freedom and flexibility, a robust IT infrastructure uniting cloud, analytics, and big data platforms will drive business excellence for your enterprise."
Higher Productivity Through Accelerated Insights and Operational Efficiency
Trianz’ analytics team can develop and deploy an ODS solution with minimal disruption to your overall business processes. By deploying a next-gen operational data store using Hortonworks Data Platform (HDP) on AWS EC2, Hadoop deployment on AWS Simple Storage Service (S3), Elastic Block Store (EBS), and AWS EC2 Instance Store, the transformation will remedy slow development life cycles, limited data processing capabilities, and heavy dependence on IT.
Experience the Trianz Difference
Trianz delivers key expertise in a new and exciting way to build integrated data solutions in the cloud with the top cloud service providers. Our consultants offer clear and constant communication, demonstrating our commitment to a technology-focused, business-forward approach.
Powered by knowledge, research, and perspectives, we enable clients to transform their business ecosystems and achieve superior performance by leveraging infrastructure, cloud, analytics, digital and security paradigms. To fast-track your ODS and data warehouse implementation, contact us today for a free consultation.